

データを伝える技術 第4回 データを見せる 前編

執筆:荻原 和樹
データの「軸」を考える
データの見せ方を考えるとき、最初に悩むのは「軸」の設定です。ここでいう「軸」とは、データの構造を考えた時にひとつの数字を分類できる「次元」を指します。
たとえばアパレル店の売り上げデータについて考えてみます。会社やシステムによってデータの持ち方は様々でしょうが、おそらく最小単位は「1人の顧客が1つの商品を買った時の売り上げ」でしょう。この場合の軸は「いつ買ったのか」「どこで買ったのか」「どのアイテムと一緒に買ったのか」「顧客の属性(年齢、性別、会員精度がある店ならその種類)」「当日の環境(気温、天気)」などがありえます。これらの軸は「顧客の年齢別売上高」のように単独で使うこともあるでしょうし、複数を組み合わせることもあるでしょう。
やや乱暴な言い方ですが、データ可視化とはこの軸を「縦の位置」「横の位置」「サイズ(棒の長さ、円の大きさなど)」「色」「奥行き(3Dで表現する場合)」「動き(アニメーションで表現する場合)」といった視覚表現に変換する行為だといえます。
先ほどのように店舗の売り上げデータを表現する場合、店舗ごとの「商品を購入した顧客の年齢」を縦軸に、「購入単価」を横軸に変換した2次元のグラフはこのように表現できます。
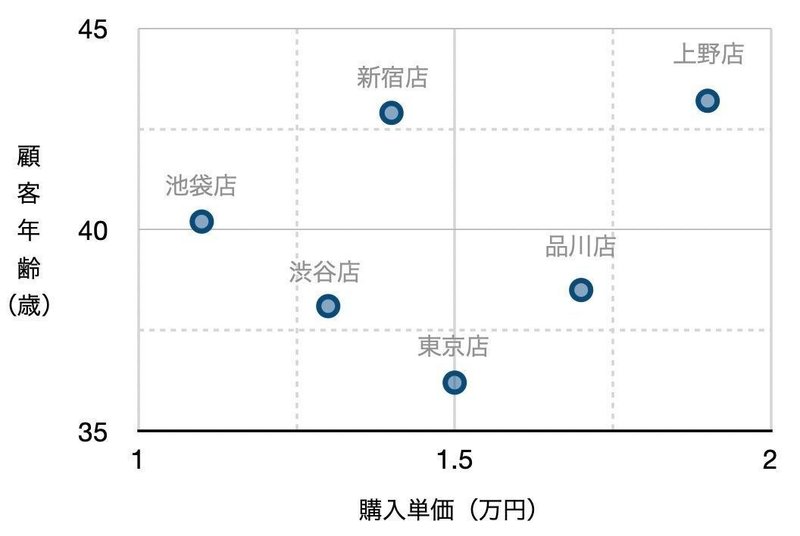
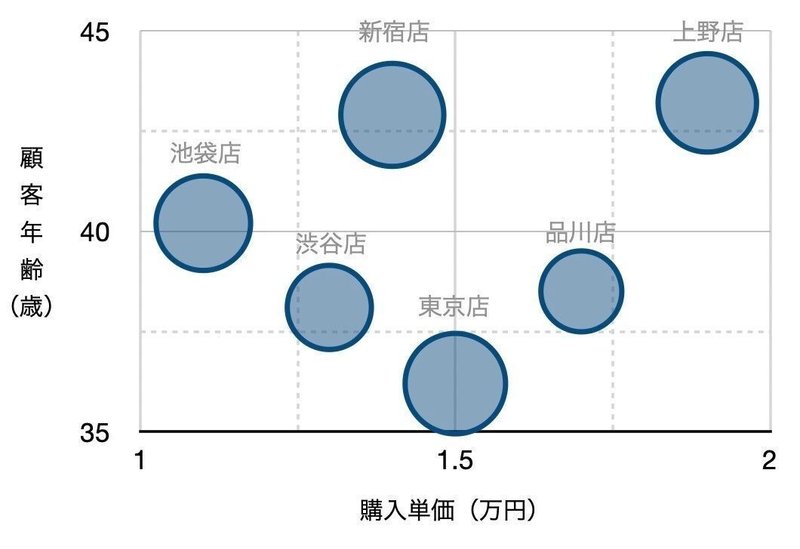
ここに軸を足すことを考えます。店舗ごとの売上高を一緒に見たい場合、すでに縦軸と横軸は他のデータに設定しているため、サイズや色など他の視覚要素を割り当てます。売上高のような「規模」を示すデータであれば、データの「種類」や「割合」のメタファーとなる色ではなく円のサイズで表現した方がよいでしょう。そこで、売上高をもとに円のサイズを調整して3次元のグラフにしてみます。
一般的な時系列を示す棒グラフも、「時系列」および「値」を軸とした2次元のグラフだといえます。このように軸を追加することで表現できるデータは増えていきますが、これをさらに発展させた事例にGapminderというデータ可視化のウェブサイトがあります。最初にアクセスすると、先ほどの可視化に加えて、アジアやヨーロッパといった地域を円の色、年ごとの推移をアニメーションに変換した動的なチャートを見ることができます。
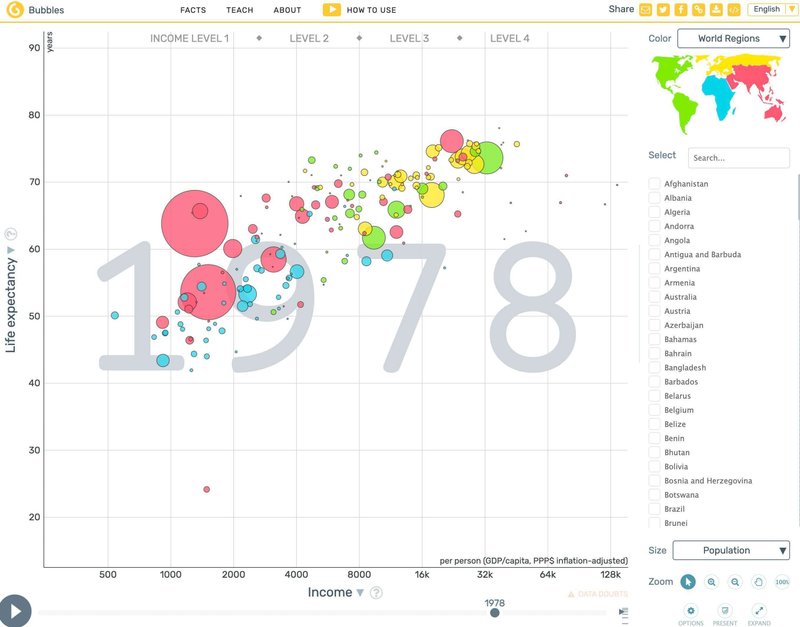
このウェブサイトは、スウェーデンのハンス・ロスリングという医師および公衆衛生学者によって設立されたギャップマインダー財団によって運営されています。同財団が開発したTrendalyzer(トレンダライザー、後にGoogleに買収された)というデータ可視化ツールを使い、世界の国々を寿命、所得、携帯電話の所有率、天然ガス生産量、失業率などなど色々な指標でビジュアライズすることができます。
ロスリングは「事実に基づいて世界を見ること」をテーマにした講演活動なども行なっており、2017年の没後にも息子オーラ・ロスリングとその妻アンナ・ロスリング・ロンランドが活動を引き継ぎました。2019年には3名を著者とする『FACTFULNESS(ファクトフルネス) 10の思い込みを乗り越え、データを基に世界を正しく見る習慣』(日経BP社)が日本でも100万部を超えるヒットとなりました。
さて、Gapminderで先ほどのアニメーションを見ると様々なことがわかります。19世紀初頭(なんと1800年からアニメーションが始まります)から現代に至るまで全世界の生活水準(平均寿命と所得)が着実に改善されてきたこと、二度の世界大戦はアニメーションでもわかるほど生活水準に対してネガティブな影響を与えたこと、寿命や所得が最初に伸びたのは欧米(初期設定では緑色や黄色のバブルで示される)だったが現代ではアジアやアフリカ地域の国々も遜色ない水準まで上がりつつあること、などなど。「平均寿命=縦軸」「1人あたり所得=横軸」「人口=円の大きさ」「地域=円の色」「時系列(年ごとの推移)=アニメーション」と実に5次元の軸を活用しているため、読み取れるメッセージも豊富です。
ただ正直なところ、5次元ものデータ可視化は複雑すぎて初見では理解できないのも事実です。ふだん見るグラフは2次元か3次元がほとんどであり、5次元もの複雑なデータ可視化になると、そのまま提示しただけではわかりにくくてユーザーが離れてしまうかもしれません。少なくとも、ユーザーが自分自身ですぐにメッセージを汲み取ってくれることは期待しないほうがよいでしょう。
Gapminderの場合、ロスリングによる巧みなプレゼンテーションが普及に大きく貢献したといえます。2006年、様々な分野の第一人者がプレゼンテーションを行う動画配信プロジェクトであるTED Talksにおいて、ロスリングはGapminderなど数種類のツールを駆使し、『ファクトフルネス』でも展開したような発展途上国に対する先進国(まさにTED Talksの視聴者です)の先入観を打ち破る解説を行っています。

軸を増やすほど表現できるデータの「深み」も増すことは確かですが、あまり煩雑になりすぎてもユーザーを遠ざける原因になってしまいます。個人的には5次元くらいが人間の認知能力の限界という気もします。軸の多いデータ可視化を扱う際には、解説を入れたり動画で説明するなど何らかのチュートリアルを設けるのも手です。
2つ以上のデータを組み合わせる
複数の軸を設定することで表現できるデータの幅は広がります。2つ以上のデータを組み合わせることで、思いがけない傾向が炙り出されたり、興味深い因果関係が示唆されることがあります。一方で「データ可視化において2つ以上のデータを同時に提示することは、良くも悪くもユーザーに因果を強く示唆する」ということは注意しなければいけません。
たとえば、日本のGDPや日経平均株価といった経済指標を、その当時の内閣で区分したグラフを目にすることがあります。政治経済の話題を扱うブログなどで、これをもって政権の経済政策が論じられるのを見たことがある方は多いと思います。
しかし冷静に考えれば、内閣の交代が即座に経済指標に影響を及ぼすわけではないでしょう。内閣や国会での議論を経て法律や省令の改正が行われ、それが行政や民間で実行され私たちの経済に影響し、結果としてGDPが動く……と考えると、一般的には数ヶ月程度の時間を要しそうです。加えて、日本の経済はひとつひとつの政策だけで上下するものではないので、景気循環や海外諸国の動向なども加味する必要があります。
もちろん内閣総理大臣や政権与党は、日本で最も経済に大きな影響を与えるプレーヤーのひとりであることは間違いないでしょうが、それがシンプルなグラフで示せるくらいに単純な関係でないことは想像がつきます。
こうしたグラフは特定の政権を持ち上げたり、逆に攻撃する材料として使われることが多いようですが、その根拠として「便利に」使われていることからもわかるように、複数のデータを同時に提示することは、両者の因果関係や関連性を強く示唆します。これは、伝えたいメッセージを文章で直接書いていなかったとしても同じです。
残念ながら、このように客観的なデータの提示と見せかけてユーザーの印象を操作しようとするデータ可視化は枚挙にいとまがありません。データ可視化は一種のコミュニケーションだと私は考えていますが、それはデータを提示するだけでも人に何らかの印象を与えることを意味します。
その印象が公平で誠実なものであれば問題ありませんが、時には今回の例のようにアンフェアな提示をしておきながら「私はデータを提示しただけであり、受けた印象はユーザーの勝手だ」と言って憚らないケースもあるのが現実です。こうした印象操作の誹りを免れないデータ可視化は厳に慎むべきであるのと同時に、データを「読む」側としても印象操作に惑わされないようにする必要があります。
もうひとつの例として、私は最近このようなグラフを目にしました。日本における喫煙率と肺がんの死亡率を時系列でプロットしたものです。
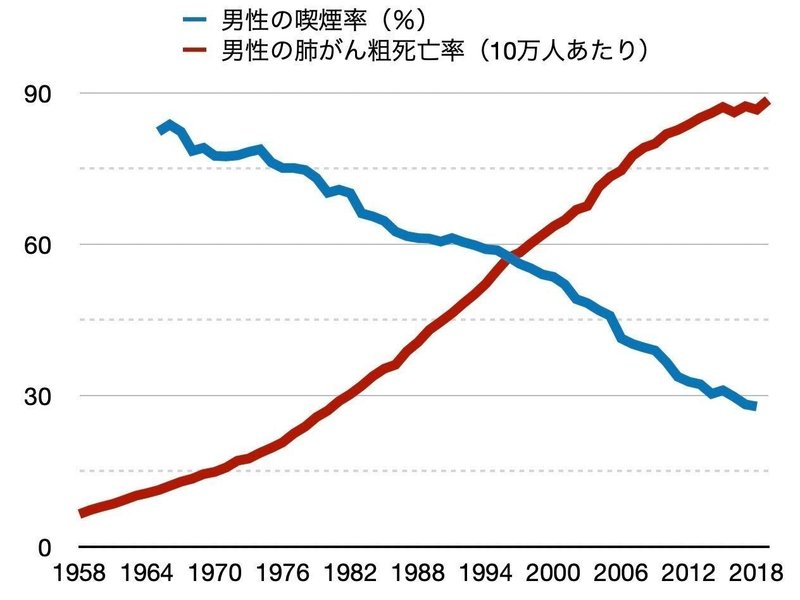
多くの人がご存知のように、喫煙が肺がんなど疾病の引き金になることは広く知られています。たばこ事業法はこれらの危険性を消費者に対して周知するよう義務付けており、たばこ製品のパッケージにはこの旨の注意文言が記載されています。2019年からはパッケージ表面積の50%以上に拡大されました。
それにもかかわらず、このグラフからは、喫煙率が1965年から低下し続ける一方で、肺がんによる死亡率は増加の一途を辿っているように読み取れます。もし何の予備知識もなくこのグラフを見せられたら、「喫煙と肺がんは関係ない」どころか「喫煙率が下がると肺がんは増える」という結論を導いてしまうかもしれません。
このカラクリは死亡率にあります。グラフで使っている死亡率は「粗死亡率」と呼ばれる指標で、死亡数と人口で単純に割ったものです。国立がん研究センター「がん情報サービス」の用語集では「一定期間の死亡数を単純にその期間の人口で割った死亡率で、年齢調整をしていない死亡率という意味で「粗」という語が付いています」と紹介されています(余談ですが会計用語の「粗利益」は「あらりえき」と読みますが、「粗死亡率」は「そしぼうりつ」と読みます)。
戦後の日本は高齢化が著しく進んだため、高齢に伴う各種のがんで死亡する割合も増えます。したがって、時系列の推移でがんによる死亡率を正しく見るには粗死亡率ではなく年齢構成を加味した指標を見なくてはいけません。
先ほどのグラフにおいて、粗死亡率を「1985年の日本人モデル人口をベースにした年齢調整後死亡率」に変えると以下のようになります。
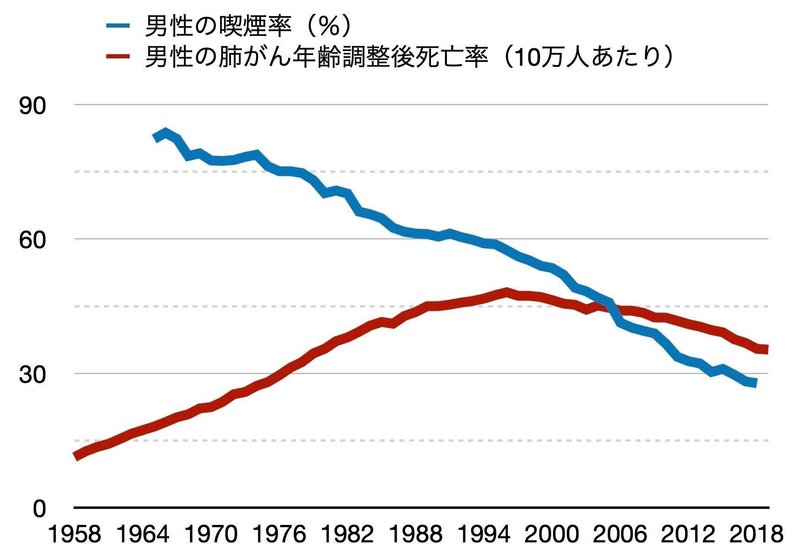
1998年ごろをピークに肺がんの死亡率が下がっていることがわかります。喫煙習慣と肺がんによる死亡には数十年のタイムラグがあることを考えても、こちらのグラフの方が直感的に納得できるものです。
日本ではたばこの販売データが1965年以降に限られますが、より長期的にデータが存在するアメリカではこの傾向がさらにはっきりと確認できます。Our World in Dataという世界の統計データを集めたウェブサイトではアメリカの喫煙率と肺がんによる死亡率をこのようにプロットしています。
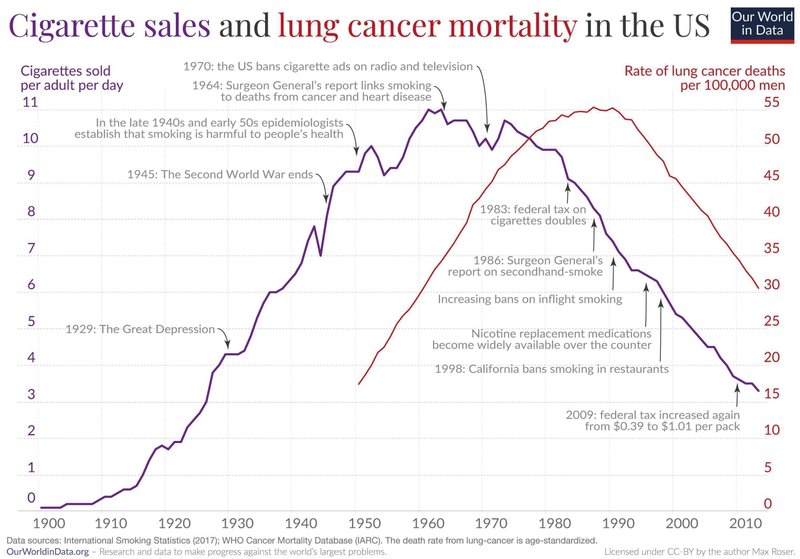
左軸は成人1人あたりが購入したたばこ本数、右軸は日本と同様に人口10万人あたりの肺がん死亡数(年齢調整後)です。1960年代にたばこの販売がピークを迎え、その後30年ほどして肺がんの死亡率も下がり始めたことがわかります。
最初に載せた粗死亡率のグラフは誤りでも嘘でもありません。データソースも国立がん研究所の正式なものであり、数字も正確です。それでも、データの定義や集計範囲を少し変えるだけでユーザーの印象を大きく操作することが可能です。今回のように広く知られたデータであれば違和感を持つこともできますが、より巧妙な印象操作であれば「嘘をつかずに人の印象を操作する」ことが可能です。
相関と因果
2つ以上のデータを組み合わせることによるデメリットは統計学の分野でも「相関関係」と「因果関係」の違いとして知られています。
相関関係とは、2つのデータ(ここではA・Bとします)が互いに連動し、Aが増減するとBも増減する関係にあることを指します。たとえば夏の気温とアイスクリームの売り上げは強く相関するでしょうが、気温と文房具の売り上げはあまり相関しないと推測できます。
統計学では、「2つのデータがどのくらい強く相関しているか」を相関係数という値で表します。0がまったく相関していない状態、1が完全に相関する状態、-1が逆に「Aが増えるほどBが減る」が成り立つ状態です。扱うデータにもよりますが、一般的には相関係数が0.6程度あれば「やや相関している」、0.8以上だと「強く相関している」と表現されることが多いようです(マイナスも同様)。図に表すとこのようになります。
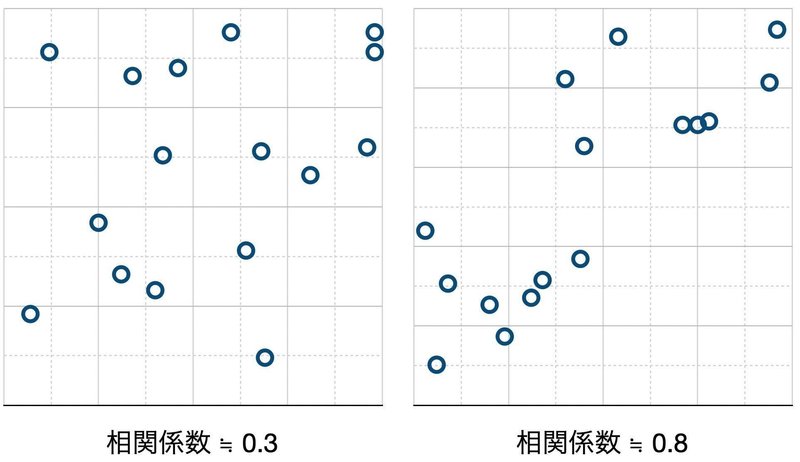
左は2つの指標があまり相関していない状態(相関係数は約0.3)、右は強く相関している状態(同0.8)です。ちなみにMicrosoft ExcelやMacのNumbersのような表計算ソフトでも「CORREL」という関数を使って簡単に相関係数が算出できます。
さて、相関関係は「2つの指標は相関しているから何らかの因果関係があるだろう」と誤解されやすいため注意が必要です。因果関係とは「Aが増減した『から』Bが増減した」状態を指します。先ほどの例でいえば、暑い「から」アイスクリームが売れたといえる状態が因果関係です。
相関は、あくまでも「データ上で2つの指標が同時に増減する」ことだけを表します。現実世界のデータは様々な要因に左右されるため、偶然の一致によってたまたま同じように推移したデータに因果関係を見出すことは重大な誤解につながります。
たとえば「アメリカにおけるプールの溺死件数とニコラス・ケイジの映画出演本数は相関する」という統計ジョークがあります。
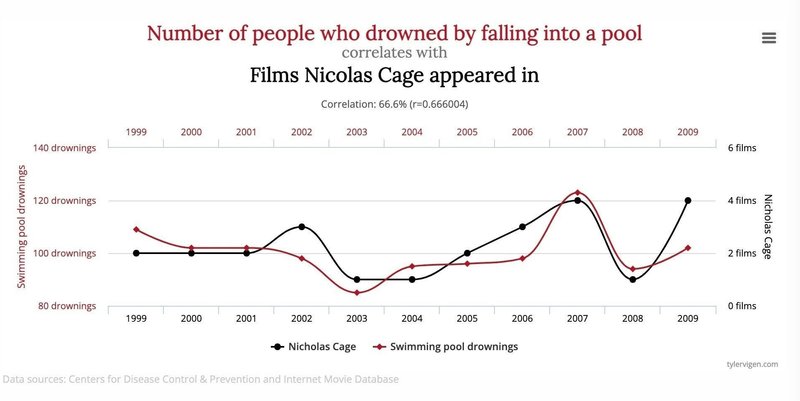
プールの溺死とニコラス・ケイジの出演映画に何らかの因果関係があるとは考えにくいため、偶然の一致である可能性が極めて高いでしょう(「絶対にない」と否定はできませんが)。このように、相関は必ずしも因果を示すとは限らず、両者の混同に気をつける必要があります。
相関が因果を示すとは限らないもうひとつのパターンが「擬似相関(spurious correlation)」または「偽相関(false correlation)」と呼ばれる現象です。これは相関する指標AとBの両方に影響を与える要素Cが存在することで、見かけ上はAとBが関連していそうに見えることを指します。
先ほどのアイスクリームの例で考えます。おそらく気温が高くなるとアイスクリームだけでなく冷えたビールも売れるでしょう。しかしアイスクリームが売れた「から」ビールも売れるわけではなく、実際には暑さがアイスクリームの売り上げとビールの売り上げの両方をもたらしていると考えるのが自然です。
最近では偶然の一致による相関も疑似相関と呼ぶことが多いようですが、統計学の用語としては第三の要因が存在するものを「擬似相関」「偽相関」と名付けています。
アイスクリームの販売を停止したからといって、ビールの売り上げがなくなるわけではありません。相関と因果の混同を避けるためには、他の様々な条件を揃えた上でアイスクリームを買った人・買わなかった人におけるビールの売り上げを見ることで因果関係を推定する方法もあります(これを統計的因果推論と呼びます)が、現実世界のデータでは簡単にいかないのが現実です。
他にも「Facebookのユーザー数とギリシャの債務は関連している(ともに2000年代半ばから急増を始めた偶然の一致と思われる)」「年収が上がるほど血圧が高くなる(ともに「年齢」という要因が疑われる)」といった偶然の一致や擬似相関と思われる事例は多くのメディアやブログなどで紹介されているので、興味のある方は「擬似相関」「spurious correlation」などの語句で検索してみるとよいでしょう。
なお、似た用語に「錯誤相関(illusory correlation)」というものがあります。こちらはデータに関連する言葉ではなく、身の回りで起きた数少ない事例に関して過度の一般化を行い、自分の中で(実際には未検証の)関係を見出してしまう現象を指します。たとえば「何も準備していない時に限って授業で問題を解くように指名されてしまう」といった、ネガティブな体験と結びついて記憶に強く残ってしまうようなケースが多いようです。日常生活では「マーフィーの法則」、株式市場では「アノマリー」と呼ばれる現象がありますが、これらに似ているかもしれません。
地図によるデータの見せ方
続いて、データ可視化においてグラフを除けば最も頻繁に使われるであろう地図表現について解説します。
データと組み合わせて地理的な傾向や分布などを表現した地図を「主題図」(Thematic map)と呼びます。主題図は路線図や天気予報など日常的にも使われる、非常にポピュラーなデータ可視化といえます。地図表現は非常に便利な可視化手法である一方で、いくつかの落とし穴もあります。
地図を可視化する際に気をつけるべき点の第一が面積の偏りです。たとえば都道府県など地図をデータによって色分けした地図は「コロプレス図(Choropleth map)」と呼ばれ、様々なデータダッシュボードや報道記事で目にしますが、日本では面積の偏りによってどうしても北海道(面積83,450平方km)が目立ちます。都道府県の中で最も小さな香川県(1,877平方km)と比べると、実に44倍を超える開きがあります。
これを解消する方法は都道府県を忠実に地図からグラフィック化するのではなく、デフォルメしてしまうことです。
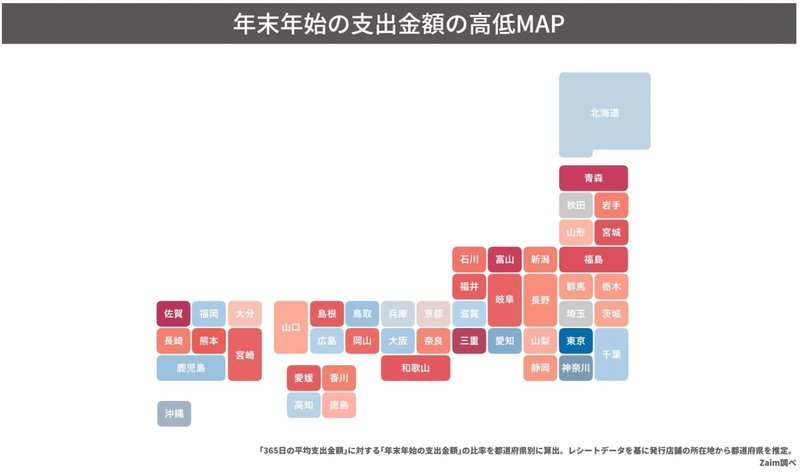
この図では北海道など一部の都道府県を大きく表示していますが、少なくとも地図そのままより面積の不均衡は緩和されたはずです。さらにこだわるのであれば都道府県の表示をすべて同じ大きさ・形にするのも手です。ただ注意点として、都道府県の形がわからず位置関係も一部で異なっているため、名前を表示しないとどの都道府県かわからないかもしれません。なお、同じ問題は市区町村や国の色分け地図でも発生します。
色分け地図による不均衡は面積だけではありません。2016年、アメリカの大統領選挙において共和党候補のドナルド・トランプと民主党候補のヒラリー・クリントンが争いましたが、New York Timesは複数の方法で選挙結果を可視化するビジュアルを制作し、リアルタイムに更新していきました。
そのひとつが「Counties」(郡)と題されたビジュアルです。アメリカは50の州に分かれており、さらにそれぞれの州を郡と呼ばれる行政単位に分けることができます(一部に例外もあります)。アメリカには全部で3000あまりの郡が存在しますが、郡ごとの選挙結果を示したのがこのビジュアルです。
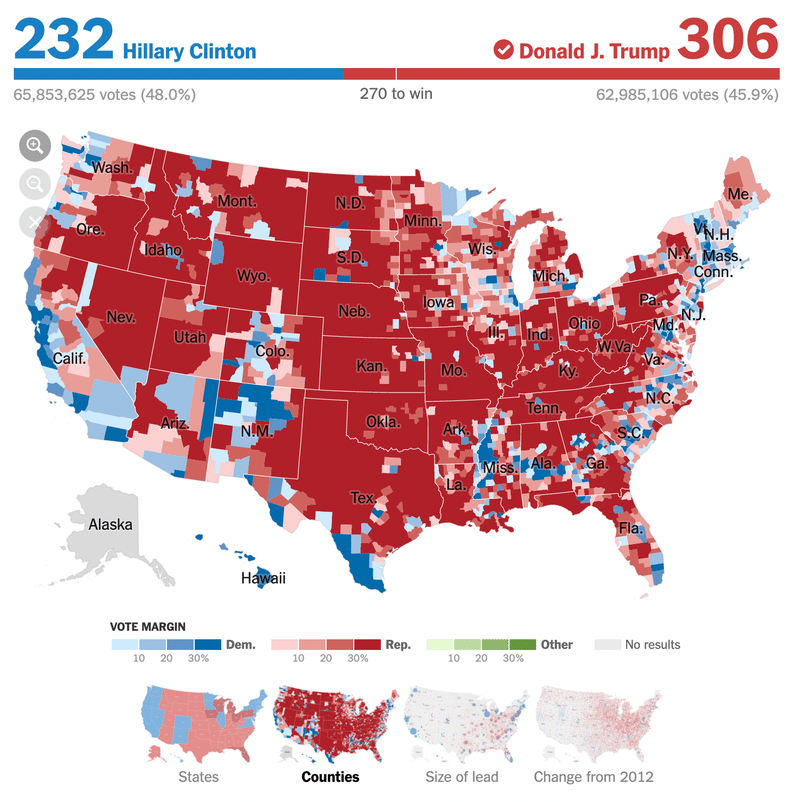
赤は共和党が優勢だった郡、青は民主党が優勢だった郡を表しています。これを見ると、トランプがアメリカのほとんどの地域で支持され圧勝しているかのような印象を受けます。
ロイター通信の記事によると、トランプは選挙での勝利から5ヶ月以上経った時点でもその地図を記者に見せて自身の大勝利をアピールしていたそうです。このエピソードはアルバート・カイロ『グラフのウソを見破る方法』(ダイヤモンド社、2020年)でも紹介されています。
勝利から5カ月以上、大統領就任から100日を2日後に控えた今も、トランプ氏の頭の中には選挙がある。中国の習近平国家主席に関する議論の途中で、大統領は話を止め、2016年の選挙結果の最新の数字を示した地図だとするコピーを配った。
「ほら、これを持っていってくれ、これが最終的な数字の地図だ」と、共和党の大統領は大統領執務室の机から、自分が勝った地域を赤で示した米国の地図を手渡した。「とてもよいだろう? どう見ても我々が赤だ」
しかし地図を冷静に眺めると違う側面が見えてきます。New York Timesの選挙結果では、得票数はトランプの圧勝どころか、むしろクリントンの方がわずかに多くなっています(トランプ6298万票、クリントン6585万票)。
この違いはどこから来るのでしょうか。理由はアメリカにおける支持基盤の違いにあります。伝統的に共和党が強い地域は、たとえばオクラホマ州など、地図からもわかるとおりアメリカの内陸部が主です。これらの地域は人口がそれほど多くない一方で面積は広い傾向にあります。他方、民主党が支持基盤とするのは沿岸部の都市です。日本でもそうですが、都市部では人口密度が高く、面積が小さい。これによって、総得票数の単純合計ではクリントンが勝っているにもかかわらず、地図上ではまるで大多数がトランプを支持しているような地図になります。
これを受けてか、New York Timesは4つある地図のバリエーションのうち、この「Counties」だけを2020年の選挙で差し替えています。
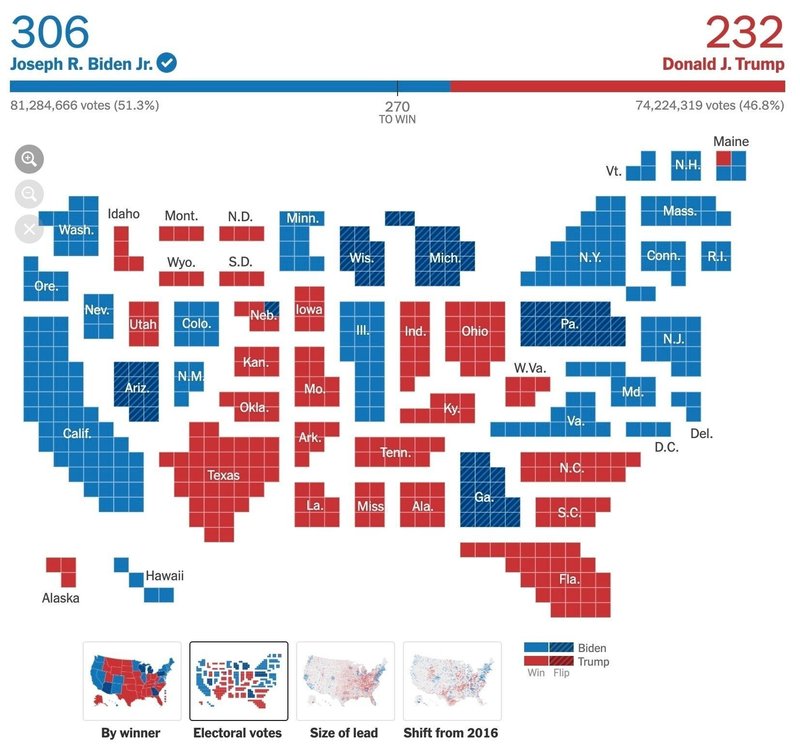
補足すると、色分け地図による可視化それ自体が不適切というわけではありません。アメリカの郡における面積と人口比や、両党の支持基盤によってはこのような配慮は不要だったかもしれません。今回のアメリカ大統領選挙では、結果として偏った印象を与えることになりましたが、他の地域別データは非常に見やすく色分け地図で表現できるかもしれません。実際に可視化してみないと実態と印象との乖離はつかみづらいのが現実です。
このようなケースの代替案は、人口の規模も加味したビジュアルにすることです。New York Timesでは「Size of lead」という種類の地図でも郡ごとの選挙結果を可視化しています。
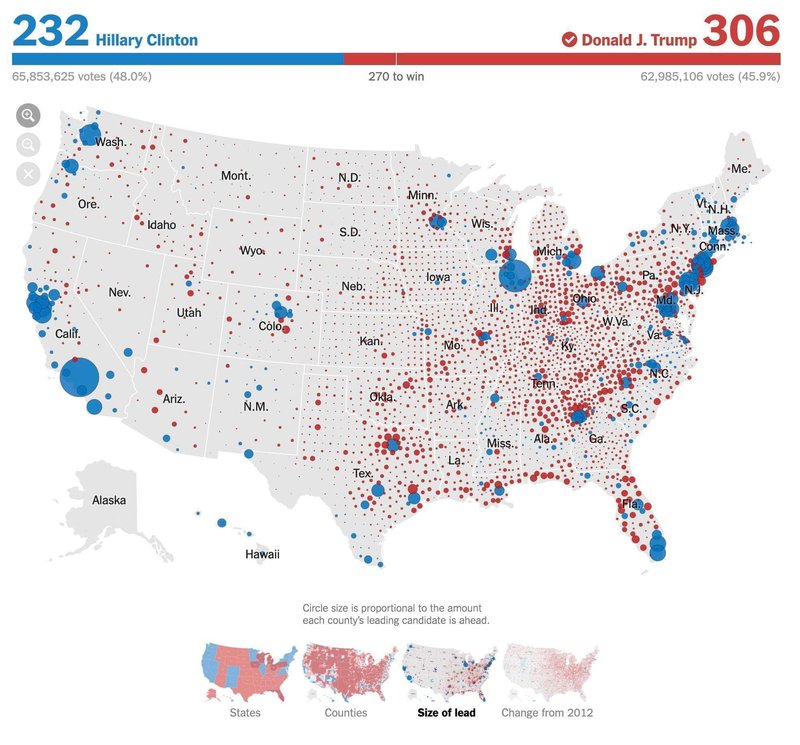
これは先ほどの「Counties」とまったく同じデータですが、郡ごとにバブル(円)で得票が表現されています。バブルの色が郡ごとの勝利政党、大きさがリードの大きさを示しています。これを見ると、赤(共和党、トランプ)は内陸部を中心とする多数の郡で小さく勝っている一方で、青(民主党、クリントン)は沿岸部など一部の地域で大きく勝っていることがわかります。この差が総得票数と先ほどの地図の不均衡につながったといえます。
では色分け地図は使わず、すべてバブルで示せばよいかというと、そういうわけでもありません。先ほどの「Size of lead」は全米3000の郡ごとにプロットしていたので不自然さはありませんが、日本の都道府県など地域のくくりが広すぎると「バブルの位置」によって誤解が生じるおそれがあります。
新型コロナの感染初期に、都道府県ごとのデータを使ってこうしたバブルでの「感染地図」を作っていた個人の方がいました。しかし都道府県の「どこ」で感染が起きたかはわからず、バブルの中心位置をすべて都道府県庁所在地に設定したため、「県庁所在地ばかりで感染が起こっているように見える」として批判を受けました。
地図表現においてバブルは「データの値」を表すと同時に、印象としては何らかの「範囲」を示すものと捉えられる場合があるため、データが足りない・粗い場合には注意が必要です。
また別角度からの注意点ですが、色分け地図を作る際には配色を単純化しすぎることで「分断」を助長しないように注意したいものです。
2016年、イギリスではEUからの離脱、俗に言う「ブレグジット」を問う国民投票が実施されました。BBCは国民投票の結果を様々なデータ可視化で伝えていましたが、その中に地域ごとの投票結果がありました。この地図では青色=離脱派と黄色=残留派がそれぞれ1色ずつで塗られているため、地域ごとに賛否がきっぱり分かれているような印象を受けます。
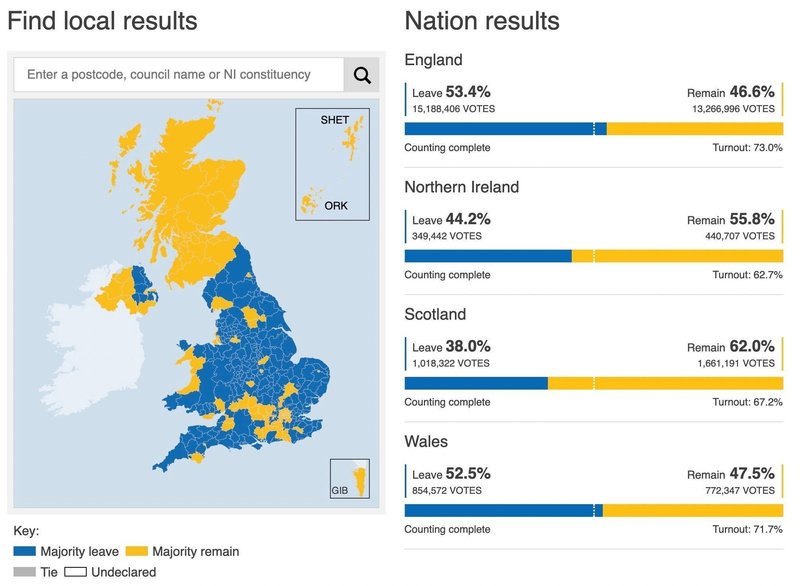
しかし全体の結果を見ると「離脱」が51.9%とかろうじて上回っている程度です。地域(イギリスでは行政区分の単位がシティ、カウンティ、カウンシルエリアなど複雑であるため一括して「地域」と表現しますが、人口でいうと日本の市区町村くらいの規模感です)ごとの結果を見ても、同じ青色でも75%超が離脱に賛成したボストンから、50.3%で「辛勝」したワトフォードまで様々です。
選挙結果であれば「1つの議席」「1人の当選者(政党)」を示す意味で色をはっきりと塗り分けることも理解できますが、今回は国民投票であり、地域ごとの集計結果がダイレクトに影響を与えるわけではありません。接戦だった地域は白色またはグレーに近くするなど、もう少し細かく色を塗り分けてもよいのではと考えます。
日本列島のデータ可視化を作る際に特有の問題として、列島が斜めに連なっているため海(余白)の比率が大きくなりがちです。北を地図の上として正方形のキャンバスに日本地図を描こうとすると、半分以上は海になってしまいます(他方、アラスカやハワイなど一部の例外を除くとアメリカ本土はおおむね4対3のちょうどいい長方形に収まる形になっており、可視化しやすそうです)。
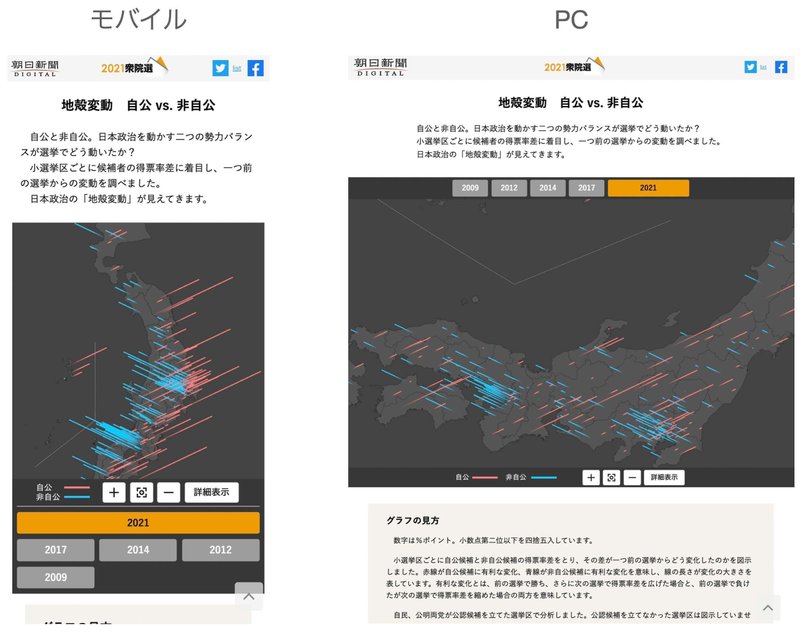
もちろん日本もそのままビジュアライズしてもよいですが、あえて方角をずらしてキャンバス上の収まりをよくする手段もあります。朝日新聞が2021年の衆議院議員選挙に合わせて公開した特設サイト「地殻変動 自公 vs. 非自公」では、縦長のモバイル端末を使っているときには北東を地図の上側にして日本列島が縦に並ぶように、PCなど横長の端末では北西を上にして横向きに列島が並ぶようにしています。これによって無駄な余白をなくし、本当に見たい陸地部分を少しでも大きく見えるようにしています。
ここまで地図によるデータ可視化を作る際の注意点や問題ばかりをご紹介してきたので、最後にインスピレーションを与えてくれる独創的な地図表現を紹介します。グラフィックデザイナー杉浦康平が1960年代末から70年代にかけて考案した「時間地図」です。

これは通常の地図表現に「到達時間」の概念を加えて地図を再構成する試みです。上の画像は東京を起点とした各地の到達時間をもとに地図を変形させています。他の大都市(大阪、名古屋など)を起点にしたものや、3Dで到達時間を高低差に置き換えた作品もあります。
1960年代は、東海道新幹線が開業(1964年)するなど、公共交通網が飛躍的に発展した時期でした。もし交通手段が徒歩しか存在しない世界であれば、ここまで地図が偏ることにはならなかったでしょう。地理的な空間と、到達時間を軸とする空間の隔たりを独創的な方法で表現した試みといえます。
杉浦自身は「いままでの俯瞰型の地図表現では見とることができない隠された時間のヒダというものが潜んでいるし、移動速度によって出発地から目的地への到達時間が変わることは、異なる時間のヒダがそこにたたみ込まれているともいえるでしょう」と語っています(『時間のヒダ、空間のシワ…[時間地図]の試み: 杉浦康平のダイアグラム・コレクション』)。
同種の試みとしては、たとえば人口に応じて世界各国の国土を拡大・縮小した地図などもあります。こうした地図はなかなかビジネスや報道では使い所が難しいかもしれませんが、空間を表現する手法としてこのような事例があることは頭の片隅にとどめておいてもよいでしょう。
つづく