

データを伝える技術 第7回 データ可視化を学ぶ意義

執筆:荻原 和樹
ここまでの連載では、データ可視化の実務やコツについて解説してきました。今回は、そもそも私たちがなぜデータ可視化を学ぶのか、について私が考えていることをお伝えします。
人はデータを「読む」ことができない
「データを読む」「データの読解力」といった表現は日常的に使われます。しかし、本当に私たちは数字で表されるデータをそのまま「読んで」いるのでしょうか?
試しに、以下のデータを数字のままで読んでみてください。

これらの数字を読んで、データの概要や傾向、何を表しているかが理解できるでしょうか。
答えはこちらです。

最初にお見せした数字は、平面上のハートを構成する点をXY座標で表したものでした。画像であればハートだと一目でわかるデータでも、数字をそのまま提示されるだけで理解できる人はほとんどいないでしょう。私は今までにいくつかの講演でこの数字を見せたことがありますが、初見でハートだとわかった方はいませんでした。私自身も予備知識のない状態で見せられたら何だかわからなかったでしょう。
基本的に、人は数字をそのまま「読む」ことができません。そもそも学校や職場で「数字の羅列を見て頭の中でグラフを作れ」といった訓練は受けていないでしょうから、考えてみれば当然のことです。
これは仕事においても同じです。たとえば売り上げの数字やアクセスデータが記された表を読むだけで「今週の売り上げは高止まりしているな」「昨日のアクセスはあまりよくなかったな」と瞬時に理解できるのは、よほど数字を見慣れているベテランだけです。
データ可視化とは何か
ここで役に立つのがデータ可視化(Data Visualization)です。「データ視覚化」とも呼ばれます。
『データビジュアライゼーション データ駆動型デザインガイド』(アンディ・カーク、朝倉書店、2021年)によると、データ可視化とは「理解を促進するためのデータ表現と提示」と定義されます。やや抽象的な表現ですが、要するにデータを(数字でない)何らかの視覚表現に変換したものはすべてデータ可視化に該当します。
私たちが見慣れた棒グラフや円グラフも、もちろんデータ可視化に含まれます。他にも、散布図、3Dグラフィック、地図などの表現もデータ可視化の事例として有名です。最近ではツールの進歩によって、静止画だけではなくアニメーションによるデータ可視化も増えています。
データ可視化は、その名前から「見せる」だけと誤解されることがありますが、インタラクティブな表現もデータ可視化に含まれます。インタラクティブとは、ボタンを押したり画面をドラッグ&ドロップすると、情報が切り替わったりズームされたりと、ユーザーの操作によって表示される情報が変わることを指します。ウェブサイトやスマートフォンアプリによって自由に拡大・縮小できる地図や、スイッチの切り替えによって集計ができるグラフなどがこれにあたります。

もとになる情報も数字データだけでなく、たとえば大量の文字情報を単語で集計して頻繁に登場する単語を大きく表示する「ワードカウント」のように、表現できる情報は数字にとどまりません。
データ可視化の範囲は広いですが、先ほどの定義にもあるように「理解を助ける」が主な目的です。座標の数字をハートに置き換えたように、グラフや地図などデータを視覚表現に置き換えることで、数字を見慣れたベテラン従業員だけでなく多くの人が同じように数字の概要を把握することができます。「データを読む」とは、ほとんどの場合「データを見る」ことに他ならないのです。
「百聞は一見にしかず」という言葉があるように、どんなに大量のデータがあっても、私たちが理解できる視覚表現に変換しないと、データの推移や傾向を把握することが極めて難しくなります。大量のデータという波にさらされる現代において、データ可視化は私たち人間がデータに溺れないための武器でもあります。
データはそこに「ある」だけでは不十分
「データは21世紀の石油である」という言葉があります。データはビジネスにおける重要な資源であり、データを活用することが成功に結びつくという意味です。数年前にはビッグデータというバズワードも注目を集めました。
たしかにデータは意思決定や現状の把握に必要な情報ですが、データは「持っている」だけでは意味がありません。石油と同様に、数々の加工を経ないとデータは活用できないものです。
私がこれを強く実感したのが、新型コロナ禍でした。
2020年2月、私は当時所属していた東洋経済オンラインで「新型コロナウイルス 国内感染の状況」というデータダッシュボード(ここでいうダッシュボードとは、さまざまなグラフや数字が表示され、ワンストップで多様なデータを定点観測できるウェブサイトやアプリを指します)を制作・公開しました。
東洋経済オンラインは文章記事が中心のメディアであり、データに関するコンテンツはあまり反響を呼ばないことが多いのですが、このときはSNSを中心として驚くほど大きな反応がありました。TwitterやFacebookで医療関係者や研究者にシェアされ、学術論文やテレビ番組で引用されました。Googleが提供する感染予測の基礎データにも採用されました。変わったところではYouTuberに紹介されたり、雑誌の連載マンガに引用されているところも見ました。東洋経済オンラインの普段の読者は主に都市部に在住・通勤するビジネスパーソンですが、それ以外の層にも確実に広がっていることが伺われました。
数字の面でも、2020年においてFacebookで12万回超、Twitterで10万回超のシェアを記録しました(Buzzsumo調べ)。これは「新型コロナウイルス」という単語が含まれる報道コンテンツの中で最も大きな数字です。
一方で、このダッシュボードでは独自情報や特別な技術を使っているわけではありません。ダッシュボードに使っているデータは、すべて公開情報です。主にデータソースとしたのは厚生労働省の報道発表ですが、公式ウェブサイトから誰でも(もちろん無料で)見ることができます。必要に応じて都道府県のサイトも参照していましたが、こちらもすべて公開情報です。
他社に先んじて速報している、というわけでもありません。たとえば本稿を執筆している2022年4月現在では、東京都は毎日16時45分にその日の感染者数を速報しますが、厚生労働省がそのデータを反映するのは翌日であり、ダッシュボードへの反映はおよそ24時間後です(これは私が退職する2021年1月時点での仕様なので、現在は変わっている可能性があります)。つまり一般メディアの速報に比べて1日程度のタイムラグがありました。
データの分析や解釈も、このダッシュボードには入っていません。以前の連載でも言及しましたが、ダッシュボードのコンセプトは「情報が錯綜する中で、確度の高い情報をユーザーが冷静に吟味できるようにする」でした。そのため可能な限り開発者=私の解釈は踏まえず、解説も最低限の用語説明やデータの注意点にとどめました。
言い換えると、スクープや速報、独自情報など、本来なら報道コンテンツが話題となるのに必要な要素が新型コロナのデータダッシュボードには何も入っていなかったといえます。価値と呼べるようなものは「データを可視化すること」だけだったと考えています。
厚生労働省による新型コロナの感染状況は、当時このような表で公開されていました。

時系列で公開されておらず、1日ごとに最新の累計数が更新される形になっているため、グラフにするためにはすべての発表を見てデータを整理し直す必要があります。また、画像で公開されているため点検・入力は手作業です。データの定義や形式も頻繁に変更されていたため、目視でのチェックは欠かせませんでした。
厚生労働省の報道発表は2020年の1月から始まっていましたが、大手のメディア(新聞社やテレビ局など)の中で、新型コロナの国内感染状況に関するデータのダッシュボードを公開したのは東洋経済オンラインが初めてでした。私は先ほど「データはすべて公開情報」と書きましたが、「公開されているが活用されていない状態」だったのです。たとえるなら、多くの人が必要としている石油が、活用されることなく垂れ流しになっているような状態でした。
データを活用するには、そのデータの構造を理解し、内容を理解し、目的に応じて編集し、さらに誤解を招く表現や不適切な使用方法を避ける必要があります。データが「公開されている」状態と「活用されている」状態には、一般に考えられているよりもずっと大きな溝があります。この溝を埋める試みがデータ可視化です。
データ可視化は「どの範囲に伝えるか」によって重視するポイントが異なる
データ可視化の「伝える範囲」は大きく3つに分けられます。たとえば自分の会社で同じ部署の同僚数人だけに見せるためのデータ可視化と、報道において広く社会一般に見せるためのデータ可視化は作り方もフォーカスすべきポイントも異なるでしょう。
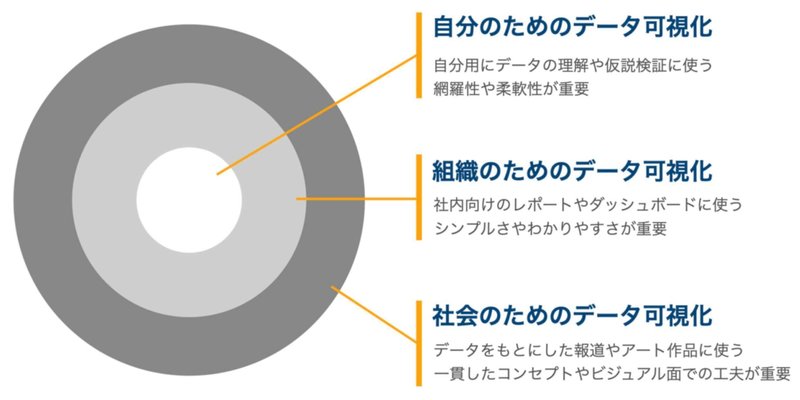
1つ目は「自分のため」のデータ可視化です。自分でExcelなどを使い、データをいろいろな角度から眺めて全体の傾向を確かめたり、ふと思いついた仮説を検討するようなイメージです。誰かに見せるためというよりは、自分が理解するための可視化です。
ここで重要なのは網羅性と柔軟性です。データに関して自分が理解していないところから始めるので、当然ながら可視化も様々な切り口に対応したものでなければなりません。明確な解釈を得るというよりは、細かい点も含めてデータが持つ様々な側面を出来る限り正確に把握することが求められます。
一方で、わかりやすいユーザーインターフェイスや明確なメッセージは自分が必要なければ省いても問題ありません。文章でいうと自分用のメモです。自分で作って自分で消費するものであるため、最低限「未来の自分」が理解できる程度であれば十分です。
2つ目は「組織のため」のデータ可視化です。自分の会社や部署に向けたデータを整備する仕事です。おそらくこのエリアが、従事している人のボリュームでいうと最も大きいでしょう。社内向けのデータダッシュボード作成、従業員向けの月次レポート作成などはここに当てはまります。
組織のためのデータ可視化では、「わかりやすさ」が最も求められます。データ可視化を作る人は、データの扱いに慣れているでしょうが、それを見て実際に活用する立場にある一般の社員はそうでないケースがほとんどです。忙しい通常業務の合間にデータを見る手間を考えると、事前の学習を必要とすることなくシンプルに一目でわかるデータ可視化を見せることが理想的です。
業務内容や扱うデータによっては、すべてのデータを可視化できなくてもよいかもしれません。また、データの解釈も必要であればつけるケースがあるでしょう。文章でいうと、社内向けの報告書やメール文章と似ています。明晰さ、ロジック、簡潔さなどが強く求められるケースです。
最後に「社会のため」のデータ可視化です。これは報道コンテンツやアート作品など、広く社会にデータを伝えるためのデータ可視化を想定しています。私が普段従事しているもの、そしてこの連載で想定している「伝えるため」のデータ可視化です。このエリアにおいては「あまり興味のない人にも知ってもらうこと」が重要になります。
仕事でデータに触れる人は明確な目的や必要性があるでしょうが、報道やアート作品ではそうとも限りません。興味の薄いユーザーにも見てもらうためには、「正確に伝わる」「わかりやすい」に加えて、データを見ることそのものが楽しいと感じてもらうような工夫を用意する必要があります。正確性や明晰さと同時に、多くの場合でデータを絞り込んだり加工したりといったデータの「編集作業」が必要になるでしょう。文章でいうと新聞記事やノンフィクションなどにあたります。事実=データを羅列するだけではなく、社会に向けたデータ可視化は一貫したコンセプトのもとに設計する必要があります。
また、ユーザーの統計知識や文化的背景といったバックグラウンドも多様です。たとえば色による区分はなるべく避ける(もしくは白黒でもわかるような色分けにする)、性別や人種などのステレオタイプを用いない、といったユニバーサルなデザインに注意を払う必要があります。場合によっては、多言語での対応も必要になるでしょう。
技術的にも多様なデバイスに対応する必要があります。業務用のデータ可視化ツールでは、PCでの閲覧を前提としているケースが多いでしょうが、今やネットのトラフィックの大部分をスマートフォンが占めています。スマートフォンでもタブレットでもPCでも、まったく同一とまでは言いませんが、ほぼ同じユーザー体験を提供しなければなりません。
データ可視化において重視すべきポイントはこれらの「届ける範囲」によって異なるため、解説記事などを参考にする場合はどんな可視化が念頭に置かれているか意識するのがおすすめです。
可視化は「データを飾りつけること」ではない
「データ可視化はデータを飾りつけること」「生のデータが最も誤解がなく、可視化は少なければ少ないほどよい」という意見をしばしば聞きますが、これはデータ可視化について表面的な理解しかしていない例です。
データ可視化は、データの「数値」だけでなく、その意味や内容と密接に結びついています。データ可視化とは複雑で理解しにくいデータから直感的に理解できる視覚表現への「翻訳」です。ごく限られた専門家しか理解できないデータという言語を、多くの人が読める日本語や英語に翻訳することがデータ可視化です。翻訳において原語の意味や内容を踏まえなければ訳せないのと同様に、データ可視化もデータの内容に目をつぶって可視化だけ行うことはできません。
たとえば、翻訳では「直訳」が常に選択されるとは限りません。コロンビア大学名誉教授のドナルド・キーンは、三島由紀夫『宴のあと』を訳す際に「白い足袋」という語を「白い手袋(white glove)」と訳しました。直訳の考え方でいえば、足袋は英語圏における靴下(white socks)が最も近しいでしょうから、手袋は明らかに「誤訳」です。しかし「白い足袋」を履いた人物の社会的地位や潔癖なところのある人物像など、小道具が暗示する要素も含めて翻訳した結果、このような翻訳になったと言われています。
データ可視化も同じように、数値をそのままグラフに変換するだけではありません。時には元のデータを一部削ったり、あるいは「補助線」として別のデータを付加する方がデータの本質を理解できる場合があります。
たとえば新型コロナの感染者数を表現するときには、その日の新規感染者数に直近7日間の平均値を付加することがあります。
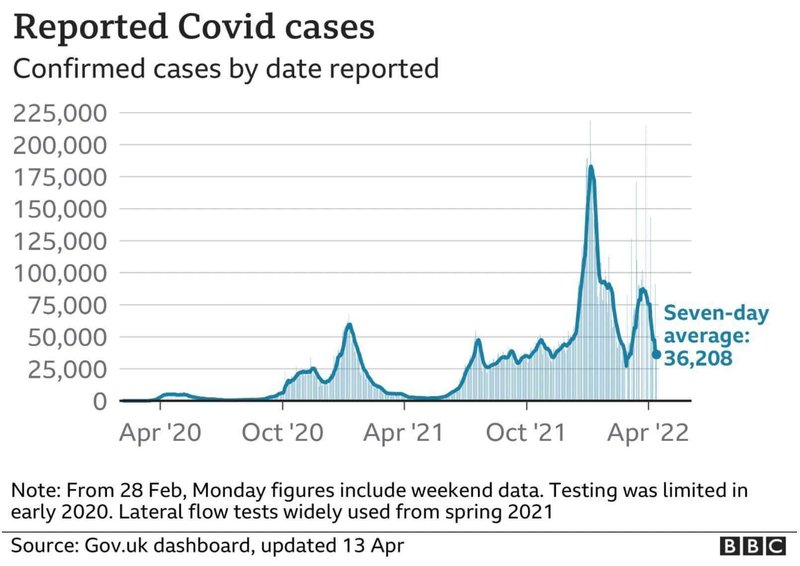
多くの諸外国でも同様ですが、新型コロナの新規感染者数は「その日に感染した人の数」ではなく「その日に感染が報告された数」です。そのため、医療機関や保健所が休日で検査・報告などを行なっていない場合、本来なら休日に報告されるはずだった数が翌営業日にずれこむことがあります。日本でも、医療機関が休む土日祝日の翌営業日(通常なら月曜日)には報告される感染者数が少なくなる傾向があります。このブレをならすために7日間平均が使われることが多いのです。
むしろ日別の感染者数だけを見て一喜一憂するよりも、7日間平均を見続ける方が直近の実態をより正確に反映していると言えます。このため上に挙げたBBCのグラフでは、棒グラフで示される感染者の実数ではなく、折れ線グラフで示される7日間平均を濃い色で表示し、強調しています。
これはデータの数字だけ見ていては出てこない発想です。データを可視化する際には、数字の裏側にある意味や文脈も踏まえて考える必要があります。
データ可視化と翻訳が似ている点は他にもあります。翻訳者によって翻訳結果が変わるように、データ可視化も誰が作るかによって結果が変わります。新型コロナや衆議院議員選挙のような社会的に注目されているトピックについては、多くのメディアがデータ可視化を活用したコンテンツを作りますが、まったく同じ可視化は存在しません。もちろん重要なデータは各社同じように表現しており、大筋では同じ情報を得ることができますが、制作者の意図や文脈によって同じデータでも可視化の結果が変わることは自然です。
データ可視化独特のスキルとは何か
データ可視化は統計学の一部分、あるいはデザインの一部分として扱われることが少なくありません。たしかにデータの扱いやデザインに精通していれば、データ可視化の工程をかなりの程度カバーできますが、それだけでは足りない部分があると私は考えています。言い換えると、そこが「データ可視化」に特有のスキルです。
先ほどの翻訳にたとえると、日本語と英語が話せる人なら必ずしも翻訳や通訳がプロ並みにできるわけではないでしょう。おそらく「翻訳」独特のスキルや訓練が必要で、それと同じことがデータ可視化についても言えます。
そのひとつが「可視化する前」の工程です。データの内容を理解し、伝えたいメッセージを決めて、可視化の手法を検討し、必要であればデータを絞り込むことはデータ可視化の非常に重要な工程です。機械的に同じ構造であってもデータの内容によって適切な可視化は違ってきますし、データの意味を考えなければ不適切な可視化を知らず知らずのうちに作ってしまう危険性すらあります。
私は前職でデータ可視化を活用した報道コンテンツを作ってきましたが、実を言うととある新興メディアに記事中の図表やデータ可視化コンテンツを「パクられた」ことがあります。もちろん偶然の一致という可能性もありますが、見る人が見れば間違いなくわかるレベルのものです(あるネットユーザーが気づいて「プチ炎上」になっていましたが、もちろん公式の反応はありませんでした)。彼らには専属のデザイナーがいるので画像それ自体は作り直していましたが、「何のデータを選び」「何を比較し」「どこにフォーカスしたタイトルにするか」などはそっくりそのままでした。
見方を変えると、私と同じくメディアで仕事をしている人であっても、自分でゼロからデータ可視化を作ることは難しいということです。「作り始める前」の工程は目に見えないので軽視されがちですが、決して誰でもできる単純作業ではありません。
最近ではデータの分析や活用が徐々に浸透してきました。それに伴い、少数ではありますがデータ可視化について扱う書籍や記事も日本国内で登場しつつあります。一方で、それらの多くはデザインや可視化の手法(グラフの種類)に焦点を当てたものが多く、「その前」の工程にフォーカスしたものはあまりないようです。この連載で強調してきたのも、「作り始める前」の工程です。
統計とデータ可視化
データから有益な示唆を引き出すための試みとして、データ可視化と統計はよく似ています。統計学のテキストで可視化について触れられていることも多いですし、両者を同時に学ぶ方も多いでしょう。
さて、まれに「統計学を駆使すればデータを可視化する必要はない」と言い切る方もいますが、可視化をまったく行わない分析はデータを大きく見誤る危険があります。
1973年、統計学者のフランク・アンスコムは後に「アンスコムの例」(またはアンスコムのカルテット)と呼ばれるデータの事例を紹介しました。この事例では、たとえば生徒1人ずつの国語と算数の点数のような、2つの数値を持つデータが11個集まったデータセットが4つあります。これらのデータセットは、いずれも平均値や分散といった統計量がほぼ同じですが、実際に可視化を行うとまったく異なるデータセットであることがわかります。
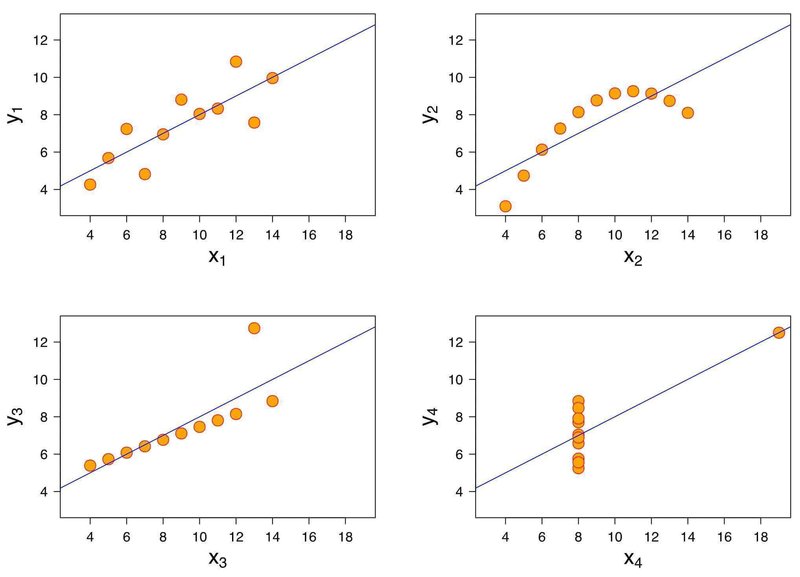
統計量だけを見ると、x(横軸)の平均と標本分散が完全に一致、y(縦軸)の平均と標本分散もほぼ(少数第2〜3位まで)一致、2つの変数の分布の傾向を示す回帰直線も完全に一致します。しかし実際の散布図を見てみると、とても同じように扱ってよいデータセットには思えません。特に3番目と4番目は外れ値(全体の傾向から大きく外れた少数のデータ)の影響が大きく、現実でこのようなデータを見たらまず外れ値の内容を精査するのがよさそうです。
これは特殊なケースではなく、統計量は同じでも実際の分布が大きく異なる散布図を生成するためのアルゴリズムも開発されています。2017年、人間と情報システムの相互作用に関する国際会議ACI CHIに提出された論文で公開されました。

中央上部にある恐竜のような散布図も含め、13個のデータセットはすべて基本的な統計量(X・Yの平均値・標準偏差、および相関係数)が一致します。ちなみにこの恐竜はDatasaurus(データ・ザウルス)と呼ばれ、この論文のインスピレーションのもとになった一種の統計ジョークです。
このように、統計的な特徴が同じであっても、可視化することによって思わぬ違いがわかる場合があります。どのような分布であるかによって、その解釈や次に行う解析も異なります。「統計に可視化は必要ない」という考え方はかなり危ういものであると言えるでしょう。
特に、具体的な分析課題が見えているときほどデータの意外な側面に気づかないものです。2020年「Genome Biology」誌に掲載された論文に「ゴリラ実験(The gorilla experiment)」と名付けられた面白い実験があります。
実験では、統計データ分析の講義を受講する学生に対して、あるデータセットが渡されます。そのデータには1786名の人々の性別、ボディマス指数(BMI)、そしてある日の歩数が載っています。これを分析する課題が出されましたが、実はデータは研究者が作成した架空のものでした。BMIを縦軸、歩数を横軸にとって散布図を描くと、以下の図bのように手を上げるゴリラが現れます。
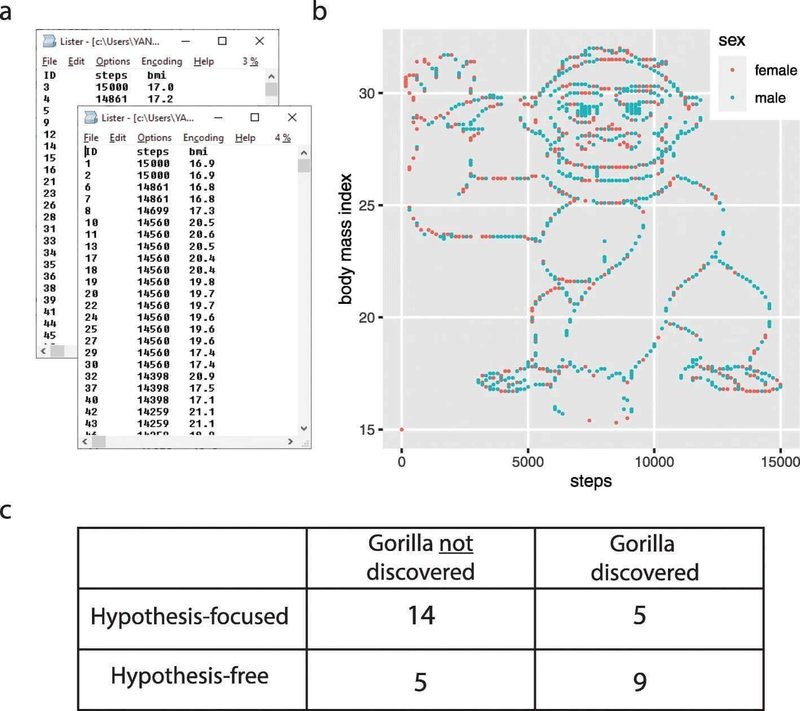
研究者は学生たちを2つのグループに分け、一方には具体的な仮説(「性別によって歩数には差がある」など3つの仮説)を検証するように指示し、もう一方には仮説を提示せず自由に検証するように促しました。その結果、仮説検証を指示された学生は19名のうち14名がゴリラに気づきませんでした。自由に検証した学生も14名のうち5名が気づかないまま課題を提出しました。
このように、データを分析する上で「可視化をしなければ気づけない事実」は思いのほか多いものです。データを活用したい目的が明確であるほど、可視化は「余計な手間」に映るものですが、その一手間をかけることによって気づけることもあります。この論文は「可視化するとゴリラが現れる」というお茶目なものでしたが、これがデータの異常や不正を示唆する分布であればどうでしょうか。データ可視化は決して「分析のおまけ」ではなく、可視化と統計の両方を駆使することで効果的にデータを把握することができます。
技術進歩とデータ可視化
近年のデジタル技術の発展により、データ可視化はますます私たちに身近なものとなりました。
最も大きいのはデータの収集や整理ができるようになったことでしょう。「ビッグデータ」という言葉が2010年代前半にバズワードとして認知されたように、大量のデータを収集して分析することが小規模な組織や個人にも可能になりました。これによって、データを理解するための手段であるデータ可視化も一緒に必要とされるようになりました。
また、ビジュアル面ではスマートフォンなど「触れる画面」が普及したことも大きい要素です。私たちは情報を紙の新聞や雑誌などではなくスマートフォンやタブレットで摂取するようになりましたが、地図を拡大・縮小したり、スイッチで画面の表示を切り替えることはもはや当たり前になりました。
これに伴い、データ可視化の制作ツールも普及しました。従来、複雑なデータ可視化を作るためにはプログラム言語を書く必要がありましたが、Tableau、QlikView、PowerBIなどいわゆるBI(ビジネスインテリジェンス)ツールが現在では広く普及しています。報道分野でもFlourish、Data Wrapperといった制作ツールが使われるケースが増えていますし、そもそも簡単なグラフであればExcelなど表計算ソフトでも作れてしまいます。
これらの技術進歩によって、データ可視化を私たちが見る・作る機会は大幅に増えました。しかしその一方で、制作が簡単になったことで「不適切なデータ可視化」を見ることも多くなりました。
不適切なデータ可視化とは、軸を無用に省略したり、自説に都合のよいデータだけ抜き出すなどして、私たちの印象を不当に操作しようとするものです。特に最近では「フェイクニュース」という言葉に代表されるように、誤った事実をあたかも正しいかのように吹聴することが増えました。
これはデータでも同様です。データ可視化の制作が容易になったということは、裏を返せば専門家でも何でもない人がデータ可視化を作れるようになったということです。その結果、まるで客観的な事実を提示しているかのように見せて偏った印象を披露するデータ可視化がSNSで広くシェアされることも増えました。
私たちがこれに対抗するためには、データのリテラシーをつけることが不可欠です。リテラシーを高めるには、そもそもデータをどのように可視化し、どう提示すべきかを学び、「作る側」の視点を学ぶことが最も重要だと考えています。危ういデータ可視化があふれる現代だからこそ、私たちはデータ可視化に関する知識をつけて騙されないようにしなければいけません。
つづく